马上注册,结交更多好友,享用更多功能,让你轻松玩转社区。
您需要 登录 才可以下载或查看,没有账号?立即注册
x
一、SQLAlchemy简介 官方文档地址: [color=inherit !important]The Database Toolkit for Python[url]www.sqlalchemy.org/[/url]
SQLAlchemy 是python中,通过ORM操作数据库的框架。简单点来说,就是帮助我们从烦冗的sql语句中解脱出来,从而不需要再去写原生的sql语句,只需要用python的语法来操作对象,就能被自动映射为sql语句。 它有几个不同的组件,可以单独使用或组合在一起。其主要组件依赖关系组织如下图所示: 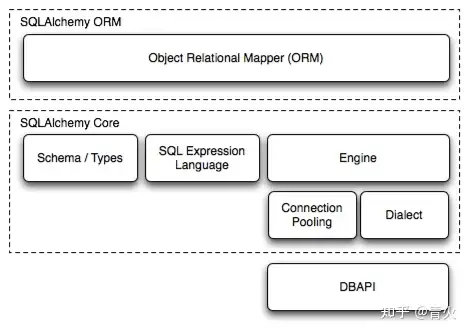 Schema / Types 类到表之间的映射规则
SQL Expression Language SQL 语句
Engine 引擎
Connection Pooling 连接池
Dialect 方言,调用不同的数据库 API(Oracle, postgresql, Mysql) 并执行对应的 SQL语句
二、安装通过PIP安装 pip install SQLAlchemy
使用setup.py安装 python setup.py install
三、连接引擎任何SQLAlchemy应用程序的开始都是一个Engine对象,此对象充当连接到特定数据库的中心源,提供被称为connection pool的对于这些数据库连接。 Engine对象通常是一个只为特定数据库服务器创建一次的全局对象,并使用一个URL字符串进行配置,该字符串将描述如何连接到数据库主机或后端。 >>> from sqlalchemy import create_engine>>> engine = create_engine('sqlite:///:memory:', echo=True)
create_engine的参数有很多,我列一些比较常用的: - echo=False -- 如果为真,引擎将记录所有语句以及 repr() 其参数列表的默认日志处理程序。
- enable_from_linting -- 默认为True。如果发现给定的SELECT语句与将导致笛卡尔积的元素取消链接,则将发出警告。
- encoding -- 默认为 utf-8
- future -- 使用2.0样式
- hide_parameters -- 布尔值,当设置为True时,SQL语句参数将不会显示在信息日志中,也不会格式化为 StatementError 对象。
- listeners -- 一个或多个列表 PoolListener 将接收连接池事件的对象。
- logging_name -- 字符串标识符,默认为对象id的十六进制字符串。
- max_identifier_length -- 整数;重写方言确定的最大标识符长度。
- max_overflow=10 -- 允许在连接池中“溢出”的连接数,即可以在池大小设置(默认为5)之上或之外打开的连接数。
- pool_size=5 -- 在连接池中保持打开的连接数
- plugins -- 要加载的插件名称的字符串列表。
四、声明映射也就是我们在Python中创建的一个类,对应着数据库中的一张表,类的每个属性,就是这个表的字段名。 这种的类对应于数据库中表的类,就称为映射类,我们要创建一个映射类,是基于基类定义的,每个映射类都要继承这个基类 declarative_base()。 >>> from sqlalchemy.orm import declarative_base>>> Base = declarative_base()
既然我们有了一个“基”类,就可以根据它定义任意数量的映射类。
我们将新建一张名为users的表,也就是用户表。一个名为User类将是我们映射此表的类。在类中,我们定义了要映射到的表的详细信息,主要是表名以及列的名称和数据类型: >>> from sqlalchemy import Column, Integer, String>>> class User(Base):... __tablename__ = 'users'...... id = Column(Integer, primary_key=True)... name = Column(String)... fullname = Column(String)... nickname = Column(String)...... def __repr__(self):... return "<User(name='%s', fullname='%s', nickname='%s')>" % (... self.name, self.fullname, self.nickname)
__tablename__ 代表表名 Column : 代表数据表中的一列,内部定义了数据类型 primary_key:主键
五、创建表到数据库通过定义User类,我们已经定义了关于表的信息,称为table metadata,也就是表的元数据。我们可以通过检查__table__属性: >>> User.__table__ Table('users', MetaData(), Column('id', Integer(), table=<users>, primary_key=True, nullable=False), Column('name', String(), table=<users>), Column('fullname', String(), table=<users>), Column('nickname', String(), table=<users>), schema=None)
开始创建表: >>> Base.metadata.create_all(engine)BEGIN...CREATE TABLE users ( id INTEGER NOT NULL, name VARCHAR, fullname VARCHAR, nickname VARCHAR, PRIMARY KEY (id))[...] ()COMMIT
六、创建映射类的实例映射完成后,现在让我们创建一个User对象的实例: >>> ed_user = User(name='ed', fullname='Ed Jones', nickname='edsnickname')>>> ed_user.name'ed'>>> ed_user.nickname'edsnickname'>>> str(ed_user.id)'None'
此时,实例对象只是在环境的内存中有效,并没有在表中真正生成数据。
七、创建会话>>> from sqlalchemy.orm import sessionmaker>>> Session = sessionmaker(bind=engine)# 实例化>>> session = Session()
我们对表的所有操作,都是通过会话实现的。 八、添加和更新对象>>> ed_user = User(name='ed', fullname='Ed Jones', nickname='edsnickname')>>> session.add(ed_user)
这里我们新增了一个用户,此时这个数据并没有被同步的数据库中,而是处于等待的状态。 只有执行了 commit() 方法后,才会真正在数据表中创建数据。 如果我们查询数据库,则首先刷新所有待处理信息,然后立即发出查询。 >>> our_user = session.query(User).filter_by(name='ed').first() >>> our_user<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>
此时得到的结果也并不是数据库表中的最终数据,而是映射类的一个对象。
九、回滚在 commit() 之前,对实例对象的属性所做的更改,可以进行回滚,回到更改之前。 >>> session.rollback()
本质上只是把某一条数据(也就是映射类的实例)从内存中删除而已,并没有对数据库有任何操作。
十、查询通过 query 关键字查询。 >>> for instance in session.query(User).order_by(User.id):... print(instance.name, instance.fullname)ed Ed Joneswendy Wendy Williamsmary Mary Contraryfred Fred Flintstone
- query.filter() 过滤
- query.filter_by() 根据关键字过滤
- query.all() 返回列表
- query.first() 返回第一个元素
- query.one() 有且只有一个元素时才正确返回
- query.one_or_none(),类似one,但如果没有找到结果,则不会引发错误
- query.scalar(),调用one方法,并在成功时返回行的第一列
- query.count() 计数
- query.order_by() 排序
query.join() 连接查询 >>> session.query(User).join(Address).\... filter(Address.email_address=='jack@google.com').\... all()[<User(name='jack', fullname='Jack Bean', nickname='gjffdd')>]
query(column.label()) 可以为字段名(列)设置别名: >>> for row in session.query(User.name.label('name_label')).all():... print(row.name_label)edwendymaryfred
aliased()为查询对象设置别名: >>> from sqlalchemy.orm import aliased>>> user_alias = aliased(User, name='user_alias')SQL>>> for row in session.query(user_alias, user_alias.name).all():... print(row.user_alias)<User(name='ed', fullname='Ed Jones', nickname='eddie')><User(name='wendy', fullname='Wendy Williams', nickname='windy')><User(name='mary', fullname='Mary Contrary', nickname='mary')><User(name='fred', fullname='Fred Flintstone', nickname='freddy')>
十一、查询常用筛选器运算符# 等于query.filter(User.name == 'ed')# 不等于query.filter(User.name != 'ed')# like和ilikequery.filter(User.name.like('%ed%'))query.filter(User.name.ilike('%ed%')) # 不区分大小写# inquery.filter(User.name.in_(['ed', 'wendy', 'jack']))query.filter(User.name.in_( session.query(User.name).filter(User.name.like('%ed%'))))# not inquery.filter(~User.name.in_(['ed', 'wendy', 'jack'])) # isquery.filter(User.name == None)query.filter(User.name.is_(None))# is notquery.filter(User.name != None)query.filter(User.name.is_not(None))# andfrom sqlalchemy import and_query.filter(and_(User.name == 'ed', User.fullname == 'Ed Jones'))query.filter(User.name == 'ed', User.fullname == 'Ed Jones')query.filter(User.name == 'ed').filter(User.fullname == 'Ed Jones')# orfrom sqlalchemy import or_query.filter(or_(User.name == 'ed', User.name == 'wendy'))# matchquery.filter(User.name.match('wendy'))
十二、使用文本SQL文字字符串可以灵活地用于Query 查询。 >>> from sqlalchemy import textSQL>>> for user in session.query(User).\... filter(text("id<224")).\... order_by(text("id")).all():... print(user.name)edwendymaryfred
>>> session.query(User).filter(text("id<:value and name=:name")).\... params(value=224, name='fred').order_by(User.id).one()<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>
十三、一对多一个用户可以有多个邮件地址,意味着我们要新建一个表与用户表进行映射和查询。 >>> from sqlalchemy import ForeignKey>>> from sqlalchemy.orm import relationship>>> class Address(Base):... __tablename__ = 'addresses'... id = Column(Integer, primary_key=True)... email_address = Column(String, nullable=False)... user_id = Column(Integer, ForeignKey('users.id'))...... user = relationship("User", back_populates="addresses")...... def __repr__(self):... return "<Address(email_address='%s')>" % self.email_address>>> User.addresses = relationship(... "Address", order_by=Address.id, back_populates="user")
ForeignKey定义两列之间依赖关系,表示关联了用户表的用户ID relationship 告诉ORMAddress类本身应链接到User类,back_populates 表示引用的互补属性名,也就是本身的表名。
十四、多对多除了表的一对多,还存在多对多的关系,例如在一个博客网站中,有很多的博客BlogPost,每篇博客有很多的Keyword,每一个Keyword又能对应很多博客。 对于普通的多对多,我们需要创建一个未映射的Table构造以用作关联表。如下所示: >>> from sqlalchemy import Table, Text>>> # association table>>> post_keywords = Table('post_keywords', Base.metadata,... Column('post_id', ForeignKey('posts.id'), primary_key=True),... Column('keyword_id', ForeignKey('keywords.id'), primary_key=True)... )
下一步我们定义BlogPost和Keyword,使用互补 relationship 构造,每个引用post_keywords表作为关联表: >>> class BlogPost(Base):... __tablename__ = 'posts'...... id = Column(Integer, primary_key=True)... user_id = Column(Integer, ForeignKey('users.id'))... headline = Column(String(255), nullable=False)... body = Column(Text)...... # many to many BlogPost<->Keyword... keywords = relationship('Keyword',... secondary=post_keywords,... back_populates='posts')...... def __init__(self, headline, body, author):... self.author = author... self.headline = headline... self.body = body...... def __repr__(self):... return "BlogPost(%r, %r, %r)" % (self.headline, self.body, self.author)>>> class Keyword(Base):... __tablename__ = 'keywords'...... id = Column(Integer, primary_key=True)... keyword = Column(String(50), nullable=False, unique=True)... posts = relationship('BlogPost',... secondary=post_keywords,... back_populates='keywords')...... def __init__(self, keyword):... self.keyword = keyword
多对多关系的定义特征是secondary关键字参数引用Table表示关联表的对象。
|




 发表于 2023-6-1 21:45:36
发表于 2023-6-1 21:45:36
